처음 작성한 코드
function solution(p1, p2) {
let middelArr = [];
p1 = p1.toUpperCase();
p2 = p2.toUpperCase();
const arr1 = new Array();
const arr2 = new Array();
for (let i = 0; i < p1.length - 1; i++) {
const str = p1.substr(i, 2);
if (str[0] >= "A" && str[0] <= "Z" && str[1] >= "A" && str[1] <= "Z") {
arr1.push(str);
}
}
for (let i = 0; i < p2.length - 1; i++) {
const str = p2.substr(i, 2);
if (str[0] >= "A" && str[0] <= "Z" && str[1] >= "A" && str[1] <= "Z") {
arr2.push(str);
}
}
let middlecount = Math.min(arr1.filter((it) => arr2.includes(it)).length, arr2.filter((it) => arr1.includes(it)).length);
arr1.sort();
arr2.sort();
middelArr.sort();
if (arr1.length + arr2.length === 0 && middlecount === 0) {
return 65536;
}
for (let i = 0; i < middlecount; i++) {
arr1.shift();
arr2.shift();
}
let temp = middlecount / (arr1.length + arr2.length + middlecount);
console.log(temp);
return Math.floor(65536 * temp);
}대문문자로 변경하고 A-Z인것을 arr1,arr2에 담았다 그리고 두개의 배열에서 서로 중복되는 교집합중 min값만 추출했고 해당 값은 교집합의 개수가 될것이다. 그래서 나는 arr1과 arr2에서 저 교집합 갯수만큼 shift를 해주면 안에 어떤 값이 되던간에 서로간에 교집합을 뺀 길이를 가지게 될 것이라고 생각했다. 합칩합을 구할 때는 교집합 + 앞전에 교집합을 뺀 각자길이를 더해주면 될 것이라 생각했고 아니면 shift 과정을 빼고 합집합에서 arr1.length+arr2.length를 하면 교집합이 한번 중복되니 교집합의 갯수만 한번 더 빼주면 된다고 생각하고 로직을 짰으나 테스트케이스 4,7,9,10,11만 계속 통과하지 못했다.. 그래서 shift로 내부에 뭐가 삭제되던간에 배열 길이만 맞으면 된다는 생각을 버리고.. 진짜 내부에 들어있는 배열로 구성하기로 마음먹었다.
const solution = (str1, str2) => {
//각각의 원소 쌍을 구하는 과정 Set으로 구현할 수 없어서 Array를 사용했다.
str1 = str1.toUpperCase();
str2 = str2.toUpperCase();
const arr1 = new Array();
const arr2 = new Array();
//이부분이 str1과 str2가 겹치므로 함수로 따로 뺐어도 됐을 것 같다.
for (let i = 0; i < str1.length - 1; i++) {
const str = str1.substr(i, 2);
if (str[0] >= "A" && str[0] <= "Z" && str[1] >= "A" && str[1] <= "Z") {
arr1.push(str);
}
}
for (let i = 0; i < str2.length - 1; i++) {
const str = str2.substr(i, 2);
if (str[0] >= "A" && str[0] <= "Z" && str[1] >= "A" && str[1] <= "Z") {
arr2.push(str);
}
}
//교집합과 합집합을 구하는 과정
const intersection = [];
const union = [];
for (let i = 0; i < arr2.length; i++) {
if (arr1.indexOf(arr2[i]) >= 0) {
intersection.push(arr1.splice(arr1.indexOf(arr2[i]), 1));
}
union.push(arr2[i]);
}
for (let i = 0; i < arr1.length; i++) {
union.push(arr1[i]);
}
if (intersection.length === 0 && union.length === 0) {
return 65536;
}
return parseInt(65536 * (intersection.length / union.length));
};설명
뉴스 클러스터링
여러 언론사에서 쏟아지는 뉴스, 특히 속보성 뉴스를 보면 비슷비슷한 제목의 기사가 많아 정작 필요한 기사를 찾기가 어렵다. Daum 뉴스의 개발 업무를 맡게 된 신입사원 튜브는 사용자들이 편리하게 다양한 뉴스를 찾아볼 수 있도록 문제점을 개선하는 업무를 맡게 되었다.
개발의 방향을 잡기 위해 튜브는 우선 최근 화제가 되고 있는 "카카오 신입 개발자 공채" 관련 기사를 검색해보았다.
- 카카오 첫 공채..'블라인드' 방식 채용
- 카카오, 합병 후 첫 공채.. 블라인드 전형으로 개발자 채용
- 카카오, 블라인드 전형으로 신입 개발자 공채
- 카카오 공채, 신입 개발자 코딩 능력만 본다
- 카카오, 신입 공채.. "코딩 실력만 본다"
- 카카오 "코딩 능력만으로 2018 신입 개발자 뽑는다"
기사의 제목을 기준으로 "블라인드 전형"에 주목하는 기사와 "코딩 테스트"에 주목하는 기사로 나뉘는 걸 발견했다. 튜브는 이들을 각각 묶어서 보여주면 카카오 공채 관련 기사를 찾아보는 사용자에게 유용할 듯싶었다.
유사한 기사를 묶는 기준을 정하기 위해서 논문과 자료를 조사하던 튜브는 "자카드 유사도"라는 방법을 찾아냈다.
자카드 유사도는 집합 간의 유사도를 검사하는 여러 방법 중의 하나로 알려져 있다. 두 집합 A, B 사이의 자카드 유사도 J(A, B)는 두 집합의 교집합 크기를 두 집합의 합집합 크기로 나눈 값으로 정의된다.
예를 들어 집합 A = {1, 2, 3}, 집합 B = {2, 3, 4}라고 할 때, 교집합 A ∩ B = {2, 3}, 합집합 A ∪ B = {1, 2, 3, 4}이 되므로, 집합 A, B 사이의 자카드 유사도 J(A, B) = 2/4 = 0.5가 된다. 집합 A와 집합 B가 모두 공집합일 경우에는 나눗셈이 정의되지 않으니 따로 J(A, B) = 1로 정의한다.
자카드 유사도는 원소의 중복을 허용하는 다중집합에 대해서 확장할 수 있다. 다중집합 A는 원소 "1"을 3개 가지고 있고, 다중집합 B는 원소 "1"을 5개 가지고 있다고 하자. 이 다중집합의 교집합 A ∩ B는 원소 "1"을 min(3, 5)인 3개, 합집합 A ∪ B는 원소 "1"을 max(3, 5)인 5개 가지게 된다. 다중집합 A = {1, 1, 2, 2, 3}, 다중집합 B = {1, 2, 2, 4, 5}라고 하면, 교집합 A ∩ B = {1, 2, 2}, 합집합 A ∪ B = {1, 1, 2, 2, 3, 4, 5}가 되므로, 자카드 유사도 J(A, B) = 3/7, 약 0.42가 된다.
이를 이용하여 문자열 사이의 유사도를 계산하는데 이용할 수 있다. 문자열 "FRANCE"와 "FRENCH"가 주어졌을 때, 이를 두 글자씩 끊어서 다중집합을 만들 수 있다. 각각 {FR, RA, AN, NC, CE}, {FR, RE, EN, NC, CH}가 되며, 교집합은 {FR, NC}, 합집합은 {FR, RA, AN, NC, CE, RE, EN, CH}가 되므로, 두 문자열 사이의 자카드 유사도 J("FRANCE", "FRENCH") = 2/8 = 0.25가 된다.
처리순서
1. str1과 str2를 각각 대문자로 변환한뒤 arr1과arr2 배열을 생성한다.
2. str1과 str2를 각각 알파벳 A-Z인것들만 앞뒤로 2개씩 묶어 arr1,arr2에 푸시한다.
3. 교집합과 합집합을 담을 intersection과 union을 생성한다.
4. arr2의 length만큼 for문을 돌리는데 교집합과 합집합을 동시에 구하기 위해
arr1에 arr2의i번째가 있는지 indexOf로 검사하고 있을시 교집합에 넣어주게 되는데 넣어줌과 동시에 arr1.splice를 하여 해당하는 것을 삭제한다.
5. 그리고 arr2의 for문을 돌면서 모든요소들을 합집합 배열에 넣는다.
6. arr1은 4-5번을 거쳐 arr2와 겹치는 요소는 삭제됐다.
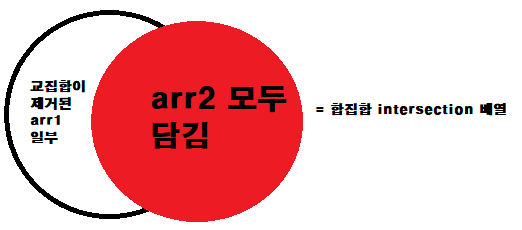
7. 교집합과 합집합이 모두 담겼고 자카드 유사도인 교집합/합집합을 하여 65536를 곱하여 정수로 리턴한다.
'일반 학습 > 코딩 테스트' 카테고리의 다른 글
| [프로그래머스] 수식 최대화 (0) | 2022.03.07 |
|---|---|
| [프로그래머스] 거리두기 확인하기 (0) | 2022.03.07 |
| [프로그래머스] 괄호 변환 (0) | 2022.03.05 |
| [프로그래머스] 문자열 압축 (0) | 2022.03.04 |
| [JavaScript] 재귀함수로 최대공약수 최소공배수 찾기 (0) | 2022.03.03 |




댓글